本文共 3763 字,大约阅读时间需要 12 分钟。
1.优化的起泡排序的排序趟数与参加排序的序列原始状态有关。(正确)
2.对任何用顶点表示活动的网络(AOV网)进行拓扑排序的结果都是唯一的。(错误)
3.在分配排序时,最高位优先分配法比最低位优先分配法简单。(错误)
4.在排序算法中每一项都与其他各项进行比较,计算出小于该项的项的个数,以确定该项的位置叫:枚举排序。
枚举排序,通常也被叫做秩排序,算法基本思想是:对每一个要排序的元素,统计小于它的所有元素的个数,从而得到该元素在整个序列中的位置,时间复杂度为O(n^2)
5.两分法插入排序所需比较次数与待排序记录的初始排列状态相关。(错误)
6. 虽然平均情况下快排和堆排时间复杂度都为O(nlogn),甚至堆排序的最坏情况下时间复杂度和辅助空间都优于快排。但是不能否认的是,虽然都是O(nlogn)级别,但是快排的常数因子要小于堆排序。
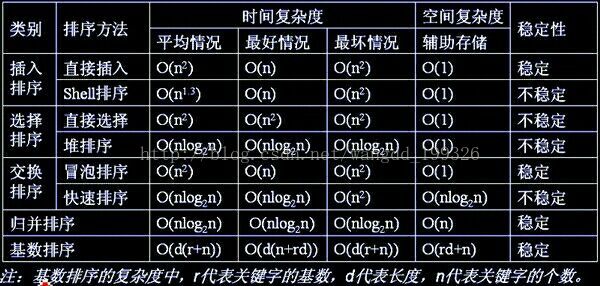
7.现有1G数据需要排序,计算资源只有1G内存可用,下列排序方法中最可能出现性能问题的是:归并排序。
分析:冒泡排序,简单选择排序,堆排序,直接插入排序,希尔排序的空间复杂度为O(1),因为需要一个临时变量来交换元素位置,(另外遍历序列时自然少不了用一个变量来做索引)。 快速排序空间复杂度为O(logn)~O(n)(因为递归调用了)。 归并排序空间复杂是O(n),需要一个大小为n的临时数组。 基数排序的空间复杂是O(n),桶排序的空间复杂度不确定。
8.现有一数列{3,2,5,7,6,8},要求按升序排序,下面说法正确的是:
快速排序,每次选择最后一个元素作为支点,需要比较12次。(快速排序,选择最后一个元素为基,第一遍需要5次比较,第二趟对8的左侧进行快速排序,需要4次比较,结果使6,7交换,第三次在6的左侧快速排序,需要2系比较,第四次在5的左侧快排,需要1次比较,加起来5+4+2+1=12次)
直接插入排序,每次需要遍历一次数组,需要5+4+3+2+1=15次。
9.排序趟数与序列的原始状态有关的排序方法是:CD。
A. 插入 B选择 C优化起泡 D 快速
分析:注意这个题问的是排序的趟数而不是时间复杂度,插入排序和选择排序不管序列的原始状态是什么都要执行n-1趟,CD就不一定了。
插入的排序趟数是固定的n-1,即使序列有序,也要依次从第二个元素开始,向前找它的插入位置。
需要区别时间复杂度和排序趟数。
10. 对n个元素的数组进行快速排序,所需要的额外空间为:O(logn)
11. 数据序列{8,9,10,4,5,6,20,1,2}只能是下列排序算法中的C后的结果。
A 选择 B 起泡 C 插入 D 堆排序
分析:A. 不可能,8不是序列中的最大或最小值。选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完。
B.不可能,2不是最大值或最小值。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成
C.插入排序:两趟排序后前三个是依次排序的
D. 不可能,8不是序列中的最大或最小值。
12. 下列哪个算法是对一个list排序的最快方法:A
A 快速排序 B 冒泡排序 C 二分插入排序 D 线性排序
分析:list采用链式结构存储,在C++ STL中的list采用双向链表存储,比较适合用快速排序进行排序,这是由快速排序不需要随机访问元素的特点决定的。因为快排从两端顺序访问元素。
冒泡排序适合list,但是算法复杂度为O(n^2),没有快速排序快。
二分插入排序算法适合顺序存储情况,不适合链式存储。
分析二:由于数据结构是链表结构,排序的时候会涉及到删除和插入操作。A选项需要调换的元素太多了,故错误。C选项才是最适合链表结构的。
分析三:list肯定指的单项链表,快速排序有两种方法,清华大学给的数据结构上一种,算法导论上一种,算法导论上那种单链表一样可以快速排序
13. 在外排序过程中,对长度为n的初始序列进行“置换-选择”排序时,可以得到的最大初始有序段的长度不超过n/2 (错误)
分析:外部排序,置换选择,在内存区保存一段数字,每次弹出内存区中最小的数字(这个数字不能比已经弹出的最大数字大),加入一个新数字,当内存区中不存在比弹出序列中最大数字还大的数字,即内存区中的数字都比上一个弹出的数字小,分段。构造第二个段,以此类推。如果待排元素有序,则只有一个归并段。长度N。
14. 快排在已经有序情况下效率最差,复杂度为:O(N^2)。
15. 排序时,若不采用计数排序的等空间换时间的方法,合并m个长度为n的已排序数组的时间复杂度最优为O(mn(logm))
分析:1).分别将m个数组的第一个数(都是各自数组的最小值)取出,建立一个最小堆。//最小堆的初始化
2).取出堆顶元素(目前最小值),放入最终的数组中。并将取出的那个元素原先的数组的下一个数放在堆顶,然后进行一次由上至下(下沉)的堆有序操作。注意:如果有一个数组遍历完,则将堆大小减1。
3).重复执行步骤2直至所有的数组都遍历完。
4).最后将堆中还剩下的m个数据按照堆排序的规则依次放入最终数组中。
整个过程中最耗时的步骤是2 3的重复。堆的有序化为O(lgm),我们需要将所有的元素(m * n个)都遍历出来让堆过滤一遍(就是找到最小值),所有大约会有 m * n 次 2 3 步的循环。
所以,最终的复杂度为m * n *lg(m)。
16. 假设你只有100MB的内存,需要对1GB的数据进行排序,最合适的算法是:归并排序、
分析:首先内存只有100Mb,而数据却有1Gb,所以肯定没法一次性放到内存去排序,只能用外部排序,而外排序通常是使用多路归并排序,即将原文件分解成多个能够一次性装入内存的部分(如这里的100Mb),分别把每一部分调入内存完成排序(根据情况选取适合的内排算法),然后对已经排序的子文件进行多路归并排序(胜者树或败者树)。
插入,冒泡,选择三个都需要把所有的数据一次性加入到内存中,才能进行。而并归排序可以完成。
17. 已知数据表A中每个元素距其最终位置不远,为了节省时间,应该采用的算法是:直接插入排序、
分析:因为每个数据里最终目标不远,说明数据基本有序,直接插入排序是数据越有序越快,最快时间复杂度可达到O(n),选择排序无论何时都是O(n^2), 快速排序越有序越慢,它要从后到前遍历找比基准小的,时间复杂度达到O(n),堆排序需要不断进行调整,时间复杂度为O(nlog2^n)。
18. 用希尔排序方法对一个数据序列进行排序时,若第一趟排序结果为9,1,4,13,7,8,20,23,15,则该趟排序采用的增量(间隔)可能:3.
分析:希尔排序:设待排序元素序列有n个,首先取gap<n作为间隔,将全部元素分为gap个子序列,所有距离为gap的元素放在同一个子序列中,在每个子序列进行直接插排。
从定义可知,在进行第一趟希尔排序后,由于执行了直接插排,每个子序列都是有序的。
根据题目,反过来,找间隔gap,使得每个子序列{a[i],a[i+gap],a[i+2*gap]....}有序,其中i~[0,n-1]。

可以看出该公式相当于a1=a0/3+1,是基于本次increment计算下一次的increment。而第一次的increment相当于a0,是给定的,不是计算得来的。
19. 对n个数字进行排序,其中两两不同的数字个数为k,n远远大于k,而n的取值区间长度超过了内存大小,时间复杂度最小可以是:O(n)。
分析:先通过hash来获得这k个数,以及每个数对应的个数,然后对k个数进行排序。复杂度为O(N),一开始要遍历n个数啊,因为不知道有多少个数,最后无法排序。所以复杂度就O(N),后面因为K很小排序就忽略了。
分析二: 两两不同的数字的个数为k,因为不知道确定的数字范围,桶排序不适合,又因为 n远远大于k, 本题使用hash表来统计,首先获得k个数及其每个数出现的次数,然后对k个数进行排序,排序的 复杂度可忽律不计,实际上就是遍历一遍n个数字,所以本位复杂度为O(n)。
20. 有一个小白程序员,写了一个只能对5个数字进行排序的函数。现在有25个不重复的数字,请问小白同学最少调用几次函数,可以找出其中最大的三个数? 7次。
分析:1、25人分5组调用,分别排序,调用5次
2、取出5组中的最大数,排序,调用1次
3、将第2步排序中最大的三组取出,假设为A,B,C,从第二步已知A[1]>B[1]>C[1],不需要再比较,选A[2]、A[3]、B[1]、B[2]、C[1]比较。不需要比较B[3]是因为A[1]已经最大了,若剩下两个数在B中,A[1]占了一个数,只剩两个位置,C[1]同理,轮到C[1]的时候,前面A[1]>B[1]已经占了两个位置。调用1次
总共 5+1+1=7次